언리얼 엔진 렌더링 파이프라인 분석
언리얼 엔진 5.7의 렌더링 파이프라인 및 렌더링 단계까지의 진입 경로를 분석합니다

· 30 min read
Unreal Engine Rendering Pipeline 분석 #
개요 #
언리얼 엔진(5.7.1)의 렌더링 파이프라인(및 렌더링 단계까지의 진입 경로)을 분석한 포스트입니다.
Threading Model #
3 스레드 모델 #
언리얼 엔진은 대부분의 게임 엔진들과 동일하게 멀티 스레드 렌더링 모델을 채택하고 있지만, 여타 엔진과 달리 3개 스레드를 사용합니다. 각 스레드는 다음과 같습니다.
- Game Thread
- Rendering Thread
- RHI Thread
Game Thread (Frame N) // 게임 로직, 물리, AI
↓ ENQUEUE_RENDER_COMMAND
Rendering Thread (Frame N-1) // RDG 구성, 컬링, 드로우콜 생성
↓ RHI Command List
RHI Thread (Frame N-2) // D3D12/Vulkan API 호출, GPU 제출
↓
GPU // 실제 렌더링 실행
3스레드 모델의 장/단점을 분석하자면 다음과 같을 것입니다.
장점
- GPU Stall 최소화
- Ideal한 상황에서 커맨드를 기입하는 Rendering 스레드와 실제 드라이버에 전달(Submit)하는 RHI 스레드를 분리함으로써 렌더링 로직의 병렬성을 더욱 극대화할 수 있음
- (Legacy API 기준) API 호출 레이턴시 은폐가 가능함.
- DX11, OpenGL과 같은 State Machine 기반 API들은 각 API들의 실행 순서가 보장되어야 했기 때문에 API콜이 끝나기 전까지 기다려야 하지만 RHI스레드가 분리됨으로써 이를 기다릴 필요가 없음
- Submit Scheduling 용이
- 렌더링 경로(Path)상의 각 렌더패스들을 병렬로 커맨드 인코딩하더라도 프레임 당 한번만 제출하는 Unity와 달리, Rendering Thread가 RHI Thread와 비동기로 동작함으로써 한 프레임에 여러 번의 Submit 호출이 용이해짐
단점
- 입력 지연
- 3스레딩 모델의 경우 최악의 상황에서 Game Thread와 RHI Thread가 2프레임 차이가 나게 되므로 유저 입장에서 입력 지연을 경험할 가능성이 있음
- 복잡도 증가
- 비동기 호출에 의한 동기화 로직이 복잡해질 수 있으며 이로 인한 버그 추적에 어려움이 다소 높음
처음에는 이러한 설계가 오버엔지니어링일 수 있다고 생각했으나, 사실 코드 복잡도의 증가를 감수하더라도 다른 엔진들과 달리 언리얼 엔진이 Lumen, Nanaite등을 필두로 GPU-Driven Rendering 정책을 채택하고 있기 때문에 Game Thread보다 Render Thread쪽의 부하가 더 높아지는 경향이 있다는 점에서 3스레드 모델을 채택하는 것이 더 바람직합니다.
Proxy 구조 #
멀티스레드 렌더링 구조를 채택할 시 Game Thread와 Render Thread 간의 데이터 동기화 및 격리에 대한 해결책이 필요합니다.
언리얼 엔진의 경우 Proxy라는 UObject의 상태 스냅샷 객체를 이용해 이를 수행합니다.
// Engine/Source/Runtime/Engine/Private/Components/PrimitiveComponent.cpp
FPrimitiveSceneProxy* UStaticMeshComponent::CreateSceneProxy()
{
return new FStaticMeshSceneProxy(this, GetStaticMesh());
}
Game Thread에서 프록시를 생성하고, ENQUEUE_RENDER_COMMAND로 Rendering Thread에 전달합니다. Rendering Thread는 이 프록시만 참조하므로 동기화 걱정이 없습니다.
Transform같은 가변성이 높은 데이터는 SendRenderTransform() 등을 이용해 매 프레임 갱신이 가능하며, StaticMesh나 Material같은 다소 무거운 데이터는 최초 생성 시에만 복사하도록 설계되어 있습니다.
모든 UObject 상속 클래스가 Proxy 데이터를 가지지는 않으며, 다음과 같이 리소스 유형에 따라 다른 패턴을 사용합니다.
| 패턴 | 예시 | 설명 |
|---|---|---|
| SceneProxy | UPrimitiveComponent | 씬에 등록되는 렌더 오브젝트 |
| RenderResource | UTexture, UStaticMesh | GPU에 상주하는 데이터 |
| RenderProxy | UMaterialInterface | 머티리얼 파라미터 캐시 |
| 없음 | UDataAsset, UBlueprint | 렌더링과 무관 |
Render Dependency Graph(RDG) #
Frostbite가 GDC에서 발표한 FrameGraph이후 대부분의 엔진에서 사용하는 Render Graph 구조의 언리얼 버전입니다. Vulkan, DX12등의 API에 명시적인 리소스 배리어가 필요하게 되면서 각 렌더 패스(와 그 안에서 사용하는 리소스들) 간의 의존성 파악이 필수적이게 되었고, 이를 수행함과 동시에 최적화 요소를 최대한 확보하는 것을 목적으로 합니다.
// Renderer/Private/BasePassRendering.cpp:1702
GraphBuilder.AddPass(
RDG_EVENT_NAME("BasePass"),
PassParameters,
ERDGPassFlags::Raster,
[&View, DrawRenderState](FRHICommandList& RHICmdList) { /* 실제 드로우 */ }
);
// 모든 패스 등록 후 한 번에 실행
GraphBuilder.Execute(); // 여기서 실제 리소스 할당, 배리어 삽입, 실행
람다 캡처 방식을 통해 Execute()호출 전까지 실행을 지연시킵니다.
구성 API #
실제 코드상에서 FRDGBuilder가 제공하는 API는 크게 4가지 분류로 나눌 수 있습니다.
새 리소스 생성 #
// RenderCore/Public/RenderGraphBuilder.h
FRDGTextureRef CreateTexture(const FRDGTextureDesc& Desc, ...);
FRDGBufferRef CreateBuffer(const FRDGBufferDesc& Desc, ...);
FRDGBufferSRVRef CreateSRV(const FRDGBufferSRVDesc& Desc);
마찬가지로, 이러한 리소스 생성 API 역시 단순히 호출 시점에는 스펙을 전달할 뿐이고 실제 리소스의 생성(GPU 메모리 할당)은 Exeucte()단계에서 이루어집니다. 또, 이러한 콜을 통해 생성된 API들은 Transiant 리소스이기 때문에 프레임이 끝나면 해제됩니다.
외부 리소스 등록 #
FRDGTextureRef RegisterExternalTexture(const TRefCountPtr<IPooledRenderTarget>& ExternalPooledTexture, ERDGTextureFlags Flags);
FRDGBufferRef RegisterExternalBuffer(const TRefCountPtr<FRDGPooledBuffer>& ExternalPooledBuffer, ERDGTextureFlags Flags);
RDG 외부에서 이미 만들어진 리소스를 그래프에 포함시키는 함수이며, 이는 여러 프레임에 걸쳐 유지되어야 하는 리소스들(ex. TAA, Motion Blur등에 사용되는 텍스쳐)을 위한 용도입니다. 여기서 외부 리소스는 상술했던 Proxy 리소스를 의미합니다.
패스 추가 #
template <typename ParameterStructType, typename ExecuteLambdaType>
FRDGPassRef AddPass(FRDGEventName&& Name, const ParameterStructType* ParameterStruct,
ERDGPassFlags Flags, ExecuteLambdaType&& ExecuteLambda);
Graph에 패스를 추가합니다. 이 때 ERDGPassFlag가 중요합니다.
// RenderCore/Public/RenderGraphDefinitions.h
enum class ERDGPassFlags : uint16
{
None = 0,
Raster = 1 << 0,
Compute = 1 << 1,
AsyncCompute = 1 << 2,
Copy = 1 << 3,
NeverCull = 1 << 4,
SkipRenderPass = 1 << 5,
NeverMerge = 1 << 6,
NeverParallel = 1 << 7,
Readback = Copy | NeverCull
};
ENUM_CLASS_FLAGS(ERDGPassFlags);
ERDGPassFlag::Raster: 그래픽스 파이프라인(RTV/DSV 바인딩)ERDGPassFlag::Compute: 동기 컴퓨트 파이프라인ERDGPassFlag::AsyncCompute: 비동기 컴퓨트(별도 커맨드 큐에서 병렬 실행)Copy리소스 복사 연산NeverCull: 최종 출력과 무관해도 제외하지 않음SkipRenderPass: 렌더 패스의 Begin/End시점을 유저가 직접 지정NeverMerge: 다른 패스와 합치지 않음NeverParallel: (렌더링 스레드 기준)단일 스레드 작업을 보장(== 렌더링 스레드 외부에서 실행하지 않음)
실행 및 추출 #
void Execute();
void QueueTextureExtraction(FRDGTextureRef Texture, TRefCountPtr<IPooledRenderTarget>* OutPtr);
Transient Resource Aliasing #
앞서 RDG에서 새 리소스를 생성하는 API를 호출하면 Transiant 리소스를 생성한다고 했습니다. 이러한 Transiant 리소스는 일종의 임시 리소스이며, 특정 패스에서만 사용되고 해제될 데이터들에 대해 GPU메모리 재사용이 가능하도록 해 줍니다. 이를 통해 GPU메모리를 절감할 수 있으며, 이는 Frostbite의 발표에서도 강조되었던 내용입니다.
IRHITransientResourceAllocator가 이러한 Transiant 리소스 할당 및 관리를 수행합니다.
Graph 실행(Execute) #
Compile → Cull → Execute 과정 #
// RenderCore/Private/RenderGraphBuilder.cpp:1751
void FRDGBuilder::Execute()
{
// 1. Compile: 의존성 그래프 구성
// - 각 Pass가 어떤 리소스를 읽고/쓰는지 분석
// - 배리어 위치 결정
// - Async compute 영역 식별
// 2. Cull: 불필요한 패스 제거
// - 최종 출력(QueueTextureExtraction)에 기여하지 않는 패스 제거
// - 경고 메시지 출력
// 3. Allocate: 리소스 할당
// - Transient 리소스 풀에서 할당
// - Aliasing 기회 탐색 (동시에 사용되지 않는 리소스끼리 메모리 공유)
// 4. Execute: 패스 실행
// - ExecutePass() 호출
// - 병렬 실행 가능한 패스는 task로 dispatch
}
실행 모드:
- Deferred Mode (기본): Pass에 패킹된 람다가 Execute() 시점에 실행됩니다.
- Immediate Mode (
-rdgimmediate또는r.RDG.ImmediateMode=1): AddPass() 호출 즉시 실행 (디버깅용)
Pass 실행 상세 #
// RenderCore/Private/RenderGraphBuilder.cpp:3448-3461
void FRDGBuilder::ExecutePass(FRHIComputeCommandList& RHICmdListPass, FRDGPass* Pass)
{
SCOPED_GPU_MASK(RHICmdListPass, Pass->GPUMask);
ExecutePassPrologue(RHICmdListPass, Pass); // 배리어 시작
Pass->Execute(RHICmdListPass); // 람다 실행
ExecutePassEpilogue(RHICmdListPass, Pass); // 배리어 종료, 렌더패스 종료
}
Prologue에서 수행:
// RenderCore/Private/RenderGraphBuilder.cpp:3361-3392
void FRDGBuilder::ExecutePassPrologue(FRHIComputeCommandList& RHICmdListPass, FRDGPass* Pass)
{
const ERDGPassFlags PassFlags = Pass->Flags;
const ERHIPipeline PassPipeline = Pass->Pipeline;
// 1. 배리어 시작 (PrologueBarriersToBegin)
if (Pass->PrologueBarriersToBegin)
{
Pass->PrologueBarriersToBegin->Submit(RHICmdListPass, PassPipeline);
}
if (Pass->PrologueBarriersToEnd)
{
Pass->PrologueBarriersToEnd->Submit(RHICmdListPass, PassPipeline);
}
// 2. RenderPass 시작 (Raster 패스인 경우)
if (EnumHasAnyFlags(PassFlags, ERDGPassFlags::Raster))
{
if (!EnumHasAnyFlags(PassFlags, ERDGPassFlags::SkipRenderPass) && !Pass->SkipRenderPassBegin())
{
static_cast<FRHICommandList&>(RHICmdListPass).BeginRenderPass(Pass->GetParameters().GetRenderPassInfo(), Pass->GetName());
}
}
// 3. UAV Overlap 시작 (validation)
BeginUAVOverlap(Pass, RHICmdListPass);
}
Epilogue에서 수행:
// RenderCore/Private/RenderGraphBuilder.cpp:3394-3446
void FRDGBuilder::ExecutePassEpilogue(FRHIComputeCommandList& RHICmdListPass, FRDGPass* Pass)
{
// 1. UAV Overlap 종료
EndUAVOverlap(Pass, RHICmdListPass);
const ERDGPassFlags PassFlags = Pass->Flags;
const ERHIPipeline PassPipeline = Pass->Pipeline;
const FRDGParameterStruct PassParameters = Pass->GetParameters();
// 2. RenderPass 종료 (Raster 패스인 경우)
if (EnumHasAnyFlags(PassFlags, ERDGPassFlags::Raster) && !EnumHasAnyFlags(PassFlags, ERDGPassFlags::SkipRenderPass) && !Pass->SkipRenderPassEnd())
{
static_cast<FRHICommandList&>(RHICmdListPass).EndRenderPass();
}
FRDGTransitionQueue Transitions;
if (Pass->EpilogueBarriersToBeginForGraphics)
{
Pass->EpilogueBarriersToBeginForGraphics->Submit(RHICmdListPass, PassPipeline, Transitions);
}
if (Pass->EpilogueBarriersToBeginForAsyncCompute)
{
Pass->EpilogueBarriersToBeginForAsyncCompute->Submit(RHICmdListPass, PassPipeline, Transitions);
}
if (Pass->EpilogueBarriersToBeginForAll)
{
Pass->EpilogueBarriersToBeginForAll->Submit(RHICmdListPass, PassPipeline, Transitions);
}
for (FRDGBarrierBatchBegin* BarriersToBegin : Pass->SharedEpilogueBarriersToBegin)
{
BarriersToBegin->Submit(RHICmdListPass, PassPipeline, Transitions);
}
if (!Transitions.IsEmpty())
{
RHICmdListPass.BeginTransitions(Transitions);
}
// 3. 배리어 종료 (EpilogueBarriersToEnd)
if (Pass->EpilogueBarriersToEnd)
{
Pass->EpilogueBarriersToEnd->Submit(RHICmdListPass, PassPipeline);
}
}
Barrier Batch System #
RDG는 여러 리소스의 전환을 배치(Batch) 로 묶어서 효율성을 높입니다:
// RenderGraphPass.h:107-168
class FRDGBarrierBatchBegin
{
public:
void AddTransition(FRDGViewableResource* Resource, FRDGTransitionInfo Info);
void AddAlias(FRDGViewableResource* Resource, const FRHITransientAliasingInfo& Info);
void CreateTransition(TConstArrayView<FRHITransitionInfo> TransitionsRHI);
void Submit(FRHIComputeCommandList& RHICmdList, ERHIPipeline Pipeline);
private:
const FRHITransition* Transition; // Batch된 전환
TArray<FRDGTransitionInfo, FRDGArrayAllocator> Transitions;
ERHIPipeline PipelinesToBegin;
ERHIPipeline PipelinesToEnd;
};
Ex:
// Graphics → AsyncCompute 전환
// 10개의 텍스처와 5개의 버퍼가 함께 전환되는 경우
// Native RHI: 15번의 개별 배리어
for (Texture : Textures)
RHICmdList.Transition(Texture, OldAccess, NewAccess);
// RDG: 1번의 batch 배리어
Batch.AddTransition(Texture1, ...);
Batch.AddTransition(Texture2, ...);
// ... (15개 추가)
Batch.Submit(RHICmdList); // 한 번에 제출
이를 통해 GPU커맨드의 개수를 최소화할 수 있습니다.
Transition Packing #
// RenderGraphPass.h:57-83
struct FRDGTransitionInfo
{
// 64-bit packed structure
uint64 AccessBefore : 21; // ERHIAccess (Before)
uint64 AccessAfter : 21; // ERHIAccess (After)
uint64 ResourceHandle : 16; // Resource index
uint64 ResourceType : 3; // Texture/Buffer
uint64 ResourceTransitionFlags : 3; // Flags
union {
struct { uint16 ArraySlice; uint8 MipIndex; uint8 PlaneSlice; } Texture;
struct { uint64 CommitSize; } Buffer;
};
};
특징:
- 64-bit 압축: Access 상태 + 리소스 정보를 64비트에 압축해 캐시 라인 점유율을 증가시킵니다.
- Subresource 단위: Mip, Array Slice 별로 개별 전환이 가능합니다.
Mesh Draw Command 생성 #
RDG와 별개로, Mesh Draw Command 시스템은 실제 Draw Call을 생성하고 최적화합니다.
###시스템 구조
FParallelMeshDrawCommandPass
├── FMeshDrawCommandPassSetupTaskContext (Setup Task)
│ ├── MeshPassProcessor (동적 커맨드 생성)
│ ├── MeshDrawCommands (결과 커맨드 배열)
│ └── InstanceCullingContext (GPU-driven culling)
│
└── BuildRenderingCommands() (RDG Pass로 제출)
├── Instance Culling 실행 (GPU)
└── Draw()/Dispatch() (실제 렌더링)
Parallel Setup Task #
// MeshDrawCommands.h:130-146
void FParallelMeshDrawCommandPass::DispatchPassSetup(
FScene* Scene,
const FViewInfo& View,
FInstanceCullingContext &&InstanceCullingContext,
EMeshPass::Type PassType, // BasePass, DepthPass, ShadowDepth...
FMeshPassProcessor* MeshPassProcessor,
const TArray<FMeshBatchAndRelevance, SceneRenderingAllocator>& DynamicMeshElements,
int32 NumDynamicMeshElements,
FMeshCommandOneFrameArray& InOutMeshDrawCommands
)
{
// Task 생성 → 백그라운드 스레드에서 실행
// - MeshPassProcessor->AddMeshBatch() 호출
// - 각 Mesh마다 draw command 생성
// - Sorting, Merging, Instancing
}
Task Context:
// MeshDrawCommands.h:54-109
class FMeshDrawCommandPassSetupTaskContext
{
// Input
const FViewInfo* View;
const FScene* Scene;
EMeshPass::Type PassType;
FMeshPassProcessor* MeshPassProcessor;
const TArray<FMeshBatchAndRelevance>* DynamicMeshElements;
// Output
FMeshCommandOneFrameArray MeshDrawCommands; // 생성된 draw commands
FInstanceCullingContext InstanceCullingContext; // GPU culling 데이터
int32 VisibleMeshDrawCommandsNum; // 통계
};
Instance Culling Integration #
// Renderer/Private/MeshDrawCommands.h
void FParallelMeshDrawCommandPass::BuildRenderingCommands(
FRDGBuilder& GraphBuilder,
const FGPUScene& GPUScene,
FInstanceCullingDrawParams& OutInstanceCullingDrawParams
)
{
// 1. Setup Task 대기
WaitForSetupTask();
// 2. GPU에서 Instance Culling 실행 (Compute Shader - BuildInstanceDrawCommands.usf)
// - Frustum culling
// - Occlusion culling (HZB)
// - Draw command compaction
// 3. Instance ID 리스트 생성
// - Visible instance IDs를 GPU 버퍼에 기록
// - Indirect draw arguments 생성
}
GPU-Driven Rendering 흐름:
CPU Setup Task → GPU Culling Pass → GPU Draw (Indirect)
(병렬) (Compute) (Raster)
↓ ↓ ↓
Draw Commands Instance Masks ExecuteIndirect()
실제 Draw 실행 #
// Renderer/Private/MeshDrawCommands.h
void FParallelMeshDrawCommandPass::Draw(
FRHICommandList& RHICmdList,
const FInstanceCullingDrawParams* InstanceCullingDrawParams
) const
{
// For each MeshDrawCommand:
// 1. Bind PSO (Pipeline State Object)
// 2. Bind Shader Bindings (Textures, Buffers, Constants)
// 3. Set Vertex/Index Buffers
// 4. DrawIndexedPrimitive() or ExecuteIndirect()
}
Dispatch 방식 (RDG 통합):
// Renderer/Private/MeshDrawCommands.h
void Dispatch(
FRDGDispatchPassBuilder& DispatchPassBuilder, // RDG parallel task builder
const FInstanceCullingDrawParams* InstanceCullingDrawParams,
float ViewportScale = 1.0f
) const;
Primitive ID Vertex Buffer Pool #
Instance ID를 vertex buffer로 전달하기 위한 풀:
// Renderer/Private/MeshDrawCommands.h
class FPrimitiveIdVertexBufferPool : public FRenderResource
{
FPrimitiveIdVertexBufferPoolEntry Allocate(FRHICommandList& RHICmdList, int32 BufferSize);
void ReturnToFreeList(FPrimitiveIdVertexBufferPoolEntry Entry);
void DiscardAll(); // 매 프레임 호출
private:
uint32 DiscardId;
TArray<FPrimitiveIdVertexBufferPoolEntry> Entries;
};
extern TGlobalResource<FPrimitiveIdVertexBufferPool> GPrimitiveIdVertexBufferPool;
사용 흐름:
// 1. Setup Task에서 크기 계산
int32 PrimitiveIdBufferSize = NumInstances * sizeof(uint32);
// 2. 버퍼 할당
FPrimitiveIdVertexBufferPoolEntry Entry =
GPrimitiveIdVertexBufferPool.Allocate(RHICmdList, PrimitiveIdBufferSize);
// 3. Instance ID 기록 (GPU 또는 CPU)
// 4. Vertex Buffer로 바인딩
// 5. 프레임 끝에 반환
GPrimitiveIdVertexBufferPool.ReturnToFreeList(Entry);
Rendering Path #
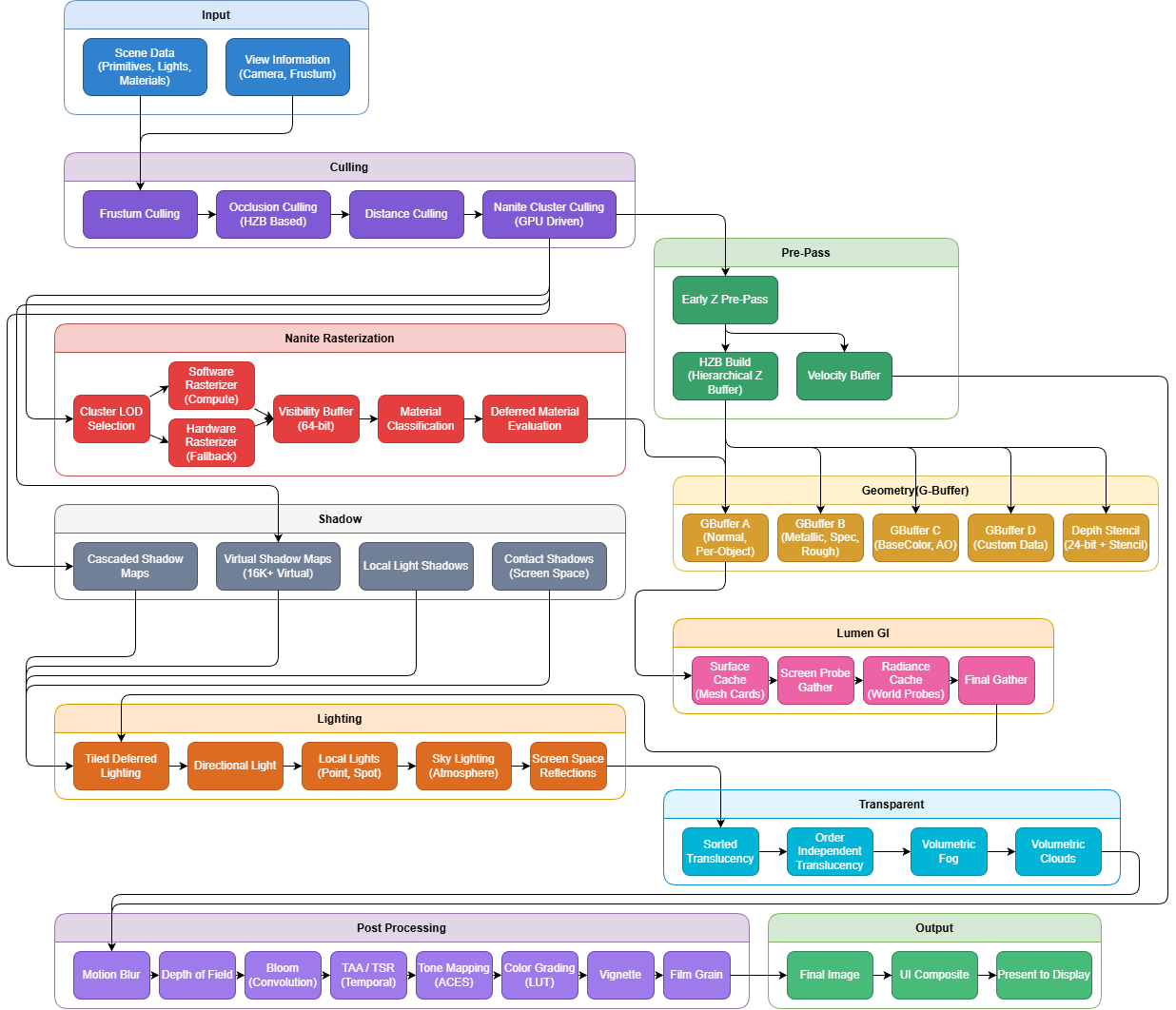
#
Rendering Passes 상세 분석 #
FDeferredShadingSceneRenderer::Render() 함수 내부에서 실행되는 각 렌더링 패스를 상세히 분석합니다.
Visibility & Culling #
렌더링의 첫 단계로, 카메라에 보이지 않는 오브젝트들을 필터링하여 GPU 부하를 줄입니다. 언리얼 엔진은 다단계 컬링 파이프라인을 통해 효율적으로 가시성을 계산합니다.
Visibility 계산 전체 흐름 #
// Engine/Source/Runtime/Renderer/Private/SceneVisibility.cpp
// ComputeViewVisibility() 호출 전 PreVisibilityFrameSetup()에서 초기화
// 1단계: Distance Culling - 카메라 거리 기반 조기 제외
// 2단계: Frustum Culling - View Frustum 밖의 오브젝트 제외
// 3단계: Occlusion Culling - 다른 오브젝트에 가려진 오브젝트 제외
// 4단계: Relevance 계산 - 각 View에 대한 Primitive의 렌더링 관련성 판단
Frustum Culling #
// Engine/Source/Runtime/Renderer/Private/SceneVisibility.cpp:773
static int32 FrustumCull(
const FScene& Scene,
FViewInfo& View,
FFrustumCullingFlags Flags,
float MaxDrawDistanceScale,
const FHLODVisibilityState* const HLODState,
const FSceneBitArray* VisibleNodes,
const FVisibilityTaskConfig& TaskConfig,
int32 TaskIndex)
{
// Task 기반 병렬 처리를 위한 Word 단위 순회
const int32 TaskWordOffset = TaskIndex * TaskConfig.FrustumCull.NumWordsPerTask;
for (int32 WordIndex = TaskWordOffset;
WordIndex < TaskWordOffset + TaskConfig.FrustumCull.NumWordsPerTask;
WordIndex++)
{
uint32 Mask = 0x1;
uint32 VisBits = 0;
for (int32 BitSubIndex = 0; BitSubIndex < NumBitsPerDWORD; BitSubIndex++, Mask <<= 1)
{
int32 Index = WordIndex * NumBitsPerDWORD + BitSubIndex;
// Hidden 플래그 체크
bool bPrimitiveIsHidden = IsPrimitiveHidden(Scene, View, Index, Flags);
bool bIsVisible = !bPrimitiveIsHidden;
// Bounding Sphere 유효성 검사
const FPrimitiveBounds& Bounds = Scene.PrimitiveBounds[Index];
bIsVisible &= Bounds.BoxSphereBounds.SphereRadius > 0;
// HLOD 강제 가시성/숨김 처리
if (HLODState)
{
if (HLODState->IsNodeForcedVisible(Index))
bShouldDistanceCull = false;
else if (HLODState->IsNodeForcedHidden(Index))
bIsVisible = false;
}
// Octree 기반 계층적 컬링 (활성화된 경우)
if (Flags.bUseVisibilityOctree)
{
uint32 OctreeNodeIndex = Scene.PrimitiveOctreeIndex[Index];
bIsVisible = (*VisibleNodes)[OctreeNodeIndex * 2];
bPartiallyOutside = (*VisibleNodes)[OctreeNodeIndex * 2 + 1];
}
// Fast Intersect: SIMD 8-Plane 테스트
if (bIsVisible && Flags.bUseFastIntersect)
{
bIsVisible = IntersectBox8Plane(
Bounds.BoxSphereBounds.Origin,
Bounds.BoxSphereBounds.BoxExtent,
PermutedPlanePtr);
}
// Distance Culling
if (bIsVisible && bShouldDistanceCull)
{
bIsVisible = !IsDistanceCulled(...);
}
}
}
}
CVar 기반 설정 옵션:
// r.Visibility.FrustumCull.Enabled: Frustum Culling 활성화
// r.Visibility.FrustumCull.UseOctree: Octree 기반 계층적 컬링
// r.Visibility.FrustumCull.UseSphereTestFirst: Sphere 테스트 우선 실행
// r.Visibility.FrustumCull.UseFastIntersect: SIMD 8-Plane 최적화 사용
// r.Visibility.FrustumCull.NumPrimitivesPerTask: Task당 Primitive 수
IntersectBox8Plane SIMD 구현 #
// Engine/Source/Runtime/Renderer/Private/SceneVisibility.cpp:527
inline bool IntersectBox8Plane(const FVector& InOrigin, const FVector& InExtent, const FPlane* PermutedPlanePtr)
{
// SIMD 레지스터에 Origin/Extent 로드
const VectorRegister Origin = VectorLoadFloat3(&InOrigin);
const VectorRegister Extent = VectorLoadFloat3(&InExtent);
// 첫 4개 Plane (Near, Far, Left, Right)
const VectorRegister PlanesX_0 = VectorLoadAligned(&PermutedPlanePtr[0]);
const VectorRegister PlanesY_0 = VectorLoadAligned(&PermutedPlanePtr[1]);
const VectorRegister PlanesZ_0 = VectorLoadAligned(&PermutedPlanePtr[2]);
const VectorRegister PlanesW_0 = VectorLoadAligned(&PermutedPlanePtr[3]);
// 나머지 4개 Plane (Top, Bottom + 2 패딩)
const VectorRegister PlanesX_1 = VectorLoadAligned(&PermutedPlanePtr[4]);
const VectorRegister PlanesY_1 = VectorLoadAligned(&PermutedPlanePtr[5]);
const VectorRegister PlanesZ_1 = VectorLoadAligned(&PermutedPlanePtr[6]);
const VectorRegister PlanesW_1 = VectorLoadAligned(&PermutedPlanePtr[7]);
// Distance 계산: dot(Origin, PlaneNormal) - PlaneW
VectorRegister Distance_0 = VectorSubtract(
VectorMultiplyAdd(OrigZ, PlanesZ_0,
VectorMultiplyAdd(OrigY, PlanesY_0,
VectorMultiply(OrigX, PlanesX_0))),
PlanesW_0);
// Push-out 거리: abs(Extent.x * PlaneNormal.x) + abs(Extent.y * PlaneNormal.y) + ...
VectorRegister PushOut_0 = VectorMultiplyAdd(AbsExtentZ, VectorAbs(PlanesZ_0),
VectorMultiplyAdd(AbsExtentY, VectorAbs(PlanesY_0),
VectorMultiply(AbsExtentX, VectorAbs(PlanesX_0))));
// Distance > PushOut이면 완전히 바깥 → false 반환
if (VectorAnyGreaterThan(Distance_0, PushOut_0))
return false;
// 두 번째 4개 Plane에 대해 동일한 테스트
// ...
return true;
}
Hierarchical Z-Buffer Occlusion Culling (HZB) #
// Engine/Source/Runtime/Renderer/Private/SceneOcclusion.cpp
static void BeginOcclusionTests(
FRHICommandList& RHICmdList,
FViewInfo& View,
const FViewOcclusionQueries& ViewQuery,
ERHIFeatureLevel::Type FeatureLevel,
uint32 DownsampleFactor,
FGraphicsPipelineStateInitializer* InGraphicsPSOInit = nullptr)
{
// 1. HZB Mip-chain 구성
// - Mip 0: 전체 해상도 Depth
// - Mip N: 2^N 다운샘플링, 각 텍셀은 해당 영역의 최대(또는 최소) 깊이
// 2. Occlusion Query 배치
// - 각 오브젝트의 Bounding Box를 해당 Mip 레벨에서 샘플링
// - Coarse Mip에서 먼저 테스트 → 실패 시 Fine Mip으로 진행
// 3. Query 결과 활용
// - GPU에서 비동기로 결과 생성
// - 다음 프레임에서 결과 읽기 (1프레임 지연)
}
HZB 생성 과정:
Full Resolution Depth (Mip 0)
↓ Max/Min Downsample
Mip 1 (1/2 해상도)
↓
Mip 2 (1/4 해상도)
↓
...
Mip N (최소 해상도)
GPU-Driven Culling (Nanite/Instance Culling) #
// Engine/Source/Runtime/Renderer/Private/InstanceCulling/InstanceCullingManager.cpp
void FInstanceCullingManager::BeginDeferredCulling(FRDGBuilder& GraphBuilder)
{
// GPU Compute Shader 기반 Culling
// 1. Frustum Culling - GPU에서 병렬 처리
// 2. Occlusion Culling - HZB 텍스처 샘플링
// 3. Distance Culling - 인스턴스별 거리 계산
// 4. Draw Command Compaction - 가시 인스턴스만 Indirect Draw Buffer에 기록
}
Instance Culling 데이터 흐름:
CPU: Primitive 등록 → GPU Scene Buffer 업로드
↓
GPU: Culling Compute Pass (BuildInstanceDrawCommands.usf)
- FrustumCull() + OcclusionCull() + DistanceCull()
↓
GPU: Visible Instance IDs → Indirect Draw Args
↓
GPU: DrawIndexedInstancedIndirect()
성능 최적화 포인트:
| 기법 | 설명 | 효과 |
|---|---|---|
| Parallel Task | Task Graph 기반 멀티스레드 컬링 | CPU 활용률 증가 |
| SIMD 8-Plane | 4개 Plane씩 병렬 테스트 | 분기 최소화 |
| Octree Culling | 계층적 공간 분할 | 대규모 씬 효율화 |
| GPU Culling | Compute Shader 기반 | CPU 병목 제거 |
| Temporal Coherence | 이전 프레임 결과 재활용 | Query 오버헤드 감소 |
장점:
- GPU에서 병렬 처리로 수천 개 오브젝트 동시 테스트
- Mip-chain으로 early-rejection 가능
- Nanite와 통합되어 자동 LOD 선택
단점:
- 1프레임 지연(이전 프레임 depth 사용)으로 빠른 카메라 이동 시 팝핑 발생 가능
- GPU Culling은 추가 Compute 비용 발생
Depth Prepass (Early-Z) #
불투명 오브젝트의 깊이만 먼저 기록하여 이후 패스에서 overdraw를 방지합니다. GPU의 Early-Z 하드웨어와 결합하여 Base Pass에서 불필요한 픽셀 셰이더 실행을 제거합니다.
RenderPrePass 전체 흐름 #
// Engine/Source/Runtime/Renderer/Private/DepthRendering.cpp:525
void FDeferredShadingSceneRenderer::RenderPrePass(
FRDGBuilder& GraphBuilder,
TArrayView<FViewInfo> InViews,
FRDGTextureRef SceneDepthTexture,
FInstanceCullingManager& InstanceCullingManager,
FRDGTextureRef* FirstStageDepthBuffer)
{
RDG_EVENT_SCOPE_STAT(GraphBuilder, Prepass, "PrePass %s %s",
GetDepthDrawingModeString(DepthPass.EarlyZPassMode),
GetDepthPassReason(DepthPass.bDitheredLODTransitionsUseStencil, ShaderPlatform));
const bool bParallelDepthPass = GRHICommandList.UseParallelAlgorithms() &&
CVarParallelPrePass.GetValueOnRenderThread();
// HMD 전용 Prepass (VR)
RenderPrePassHMD(GraphBuilder, InViews, SceneDepthTexture);
// Dithered LOD Transition을 위한 Stencil 초기화
if (DepthPass.IsRasterStencilDitherEnabled())
{
AddDitheredStencilFillPass(GraphBuilder, InViews, SceneDepthTexture, DepthPass);
}
// Primary Depth Pass 렌더링
if (DepthPass.EarlyZPassMode != DDM_None)
{
RenderDepthPass(EMeshPass::DepthPass);
}
// Secondary Depth Pass (WPO, Dithered LOD 등을 위한 2단계 깊이)
if (bUsesSecondStageDepthPass)
{
// 1단계 깊이 복사
*FirstStageDepthBuffer = GraphBuilder.CreateTexture(..., TEXT("FirstStageDepthBuffer"));
DepthCopy::AddViewDepthCopyPSPass(GraphBuilder, View, SceneDepthTexture, *FirstStageDepthBuffer);
// 2단계 깊이 렌더링
RenderDepthPass(EMeshPass::SecondStageDepthPass);
}
}
Parallel Depth Pass 구현 #
// Engine/Source/Runtime/Renderer/Private/DepthRendering.cpp:548
auto RenderDepthPass = [&](uint8 DepthMeshPass)
{
if (bParallelDepthPass)
{
for (int32 ViewIndex = 0; ViewIndex < InViews.Num(); ++ViewIndex)
{
FViewInfo& View = InViews[ViewIndex];
View.BeginRenderView();
FDepthPassParameters* PassParameters = GetDepthPassParameters(GraphBuilder, View, SceneDepthTexture);
if (auto* Pass = View.ParallelMeshDrawCommandPasses[DepthMeshPass])
{
// GPU Scene에서 Instance Culling 데이터 빌드
Pass->BuildRenderingCommands(GraphBuilder, Scene->GPUScene, PassParameters->InstanceCullingDrawParams);
// Parallel Dispatch: 여러 Worker Thread에서 Draw Command 인코딩
GraphBuilder.AddDispatchPass(
RDG_EVENT_NAME("DepthPassParallel"),
PassParameters,
ERDGPassFlags::Raster,
[Pass, PassParameters](FRDGDispatchPassBuilder& DispatchPassBuilder)
{
Pass->Dispatch(DispatchPassBuilder, &PassParameters->InstanceCullingDrawParams);
});
}
}
}
else
{
// Non-parallel: 단일 스레드 렌더링
GraphBuilder.AddPass(
RDG_EVENT_NAME("DepthPass"),
PassParameters,
ERDGPassFlags::Raster,
[&View, Pass, PassParameters](FRDGAsyncTask, FRHICommandList& RHICmdList)
{
SetStereoViewport(RHICmdList, View, 1.0f);
Pass->Draw(RHICmdList, &PassParameters->InstanceCullingDrawParams);
});
}
};
EDepthDrawingMode 상세 #
// Engine/Source/Runtime/Renderer/Public/DepthRendering.h
enum EDepthDrawingMode
{
DDM_None, // Depth Prepass 비활성화
DDM_NonMaskedOnly, // Masked 머티리얼 제외 (Alpha Test 없는 오브젝트만)
DDM_AllOccluders, // 모든 Occluder (bUseAsOccluder=true인 오브젝트)
DDM_AllOpaque, // 모든 불투명 오브젝트
};
EarlyZPassMode 선택 로직:
// Engine/Source/Runtime/Renderer/Private/DepthRendering.cpp
EDepthDrawingMode EarlyZPassMode = DDM_None;
// Forward Shading: Depth만 먼저 그려야 라이팅 계산 전에 Z-test 가능
if (bForwardShading)
EarlyZPassMode = DDM_AllOpaque;
// Deferred Shading: 씬 복잡도에 따라 결정
else if (bDeferredShading)
{
// Nanite 활성화 시: Nanite가 자체 depth 생성하므로 Non-Nanite만 처리
if (bNaniteEnabled)
EarlyZPassMode = DDM_NonMaskedOnly;
// 복잡한 씬: 모든 Occluder 렌더링
else if (NumOccluders > OccluderThreshold)
EarlyZPassMode = DDM_AllOccluders;
// 단순한 씬: Overdraw가 적으므로 Prepass 스킵 가능
else
EarlyZPassMode = DDM_None;
}
EarlyZPassMode 선택 기준:
| 모드 | 렌더링 대상 | 사용 조건 | 장점 |
|---|---|---|---|
| DDM_None | 없음 | 단순 씬, Forward | CPU/GPU 비용 없음 |
| DDM_NonMaskedOnly | Opaque만 (Masked 제외) | 대부분 불투명, Nanite | Alpha test 오버헤드 회피 |
| DDM_AllOccluders | bUseAsOccluder=true | 복잡한 씬 | 최대 Overdraw 감소 |
| DDM_AllOpaque | 모든 Opaque | Nanite 미사용 복잡 씬 | 모든 불투명 오브젝트 Z-buffer 등록 |
Depth Pass Shader Binding #
// Engine/Source/Runtime/Renderer/Private/DepthRendering.cpp
void SetupDepthPassState(FMeshPassProcessorRenderState& DrawRenderState)
{
// Depth Write 활성화, Color Write 비활성화
DrawRenderState.SetBlendState(TStaticBlendStateWriteMask<CW_NONE>::GetRHI());
// Depth Test: Less or Equal (기존 깊이보다 가깝거나 같으면 통과)
DrawRenderState.SetDepthStencilState(
TStaticDepthStencilState<true, CF_DepthNearOrEqual>::GetRHI());
}
Second Stage Depth Pass #
World Position Offset(WPO)이나 Dithered LOD Transition을 사용하는 머티리얼의 경우, 깊이가 2단계로 처리됩니다:
1단계 (Primary): 일반 Opaque 오브젝트 → SceneDepth
↓
깊이 복사 → FirstStageDepthBuffer
↓
2단계 (Secondary): WPO/Dithered 오브젝트 → SceneDepth 갱신
사용 사례:
- WPO (World Position Offset): 버텍스 셰이더에서 위치를 변경하는 머티리얼 (풀, 나무 등)
- Dithered LOD Transition: LOD 전환 시 디더링 효과로 부드러운 전환
Depth Prepass 최적화 고려사항 #
| 항목 | 설명 |
|---|---|
| Draw Call Batching | 동일한 머티리얼의 메시를 그룹화하여 State Change 최소화 |
| Front-to-Back Sorting | 카메라에 가까운 오브젝트 먼저 렌더링 → Early-Z 효율 극대화 |
| Parallel Command Encoding | bParallelDepthPass로 멀티스레드 Draw Command 생성 |
| Masked 제외 | Alpha Test는 Early-Z를 비활성화하므로 DDM_NonMaskedOnly 권장 |
| Nanite 연동 | Nanite 메시는 자체 Depth Pass 사용, 중복 렌더링 방지 |
Base Pass (G-Buffer) #
Deferred Shading의 핵심으로, 모든 불투명 오브젝트의 지오메트리/머티리얼 정보를 G-Buffer에 기록합니다. 이 단계에서는 라이팅 계산 없이 머티리얼 속성만 저장합니다.
RenderBasePass 전체 흐름 #
// Engine/Source/Runtime/Renderer/Private/BasePassRendering.cpp:1071
void FDeferredShadingSceneRenderer::RenderBasePass(
FDeferredShadingSceneRenderer& Renderer,
FRDGBuilder& GraphBuilder,
TArrayView<FViewInfo> InViews,
FSceneTextures& SceneTextures,
const FDBufferTextures& DBufferTextures,
FExclusiveDepthStencil::Type BasePassDepthStencilAccess,
FRDGTextureRef ForwardShadowMaskTexture,
FInstanceCullingManager& InstanceCullingManager,
bool bNaniteEnabled,
FNaniteShadingCommands& NaniteBasePassShadingCommands,
const TArrayView<Nanite::FRasterResults>& NaniteRasterResults)
{
// 1. Parallel Base Pass 활성화 여부 결정
const bool bEnableParallelBasePasses = GRHICommandList.UseParallelAlgorithms() &&
CVarParallelBasePass.GetValueOnRenderThread();
const bool bDoParallelBasePass = bEnableParallelBasePasses && !bDebugViewMode;
// 2. Clear Method 결정 (r.ClearSceneMethod CVar)
// - 0: No clear
// - 1: RHICmdList.Clear (하드웨어 클리어)
// - 2: Far-Z Quad (전체 화면 쿼드로 클리어)
// 3. G-Buffer Render Target 설정
TStaticArray<FTextureRenderTargetBinding, MaxSimultaneousRenderTargets> BasePassTextures;
uint32 BasePassTextureCount = SceneTextures.GetGBufferRenderTargets(BasePassTextures);
// Substrate MRT 추가 (Substrate 활성화 시)
Substrate::AppendSubstrateMRTs(Renderer, BasePassTextureCount, BasePassTextures);
// 4. G-Buffer 클리어 (필요 시)
if (bRequiresRHIClear)
{
GraphBuilder.AddPass(RDG_EVENT_NAME("GBufferClear"), PassParameters, ERDGPassFlags::Raster,
[PassParameters, SceneColorClearValue](FRDGAsyncTask, FRHICommandList& RHICmdList)
{
// MRT Clear 또는 Shader Clear
DrawClearQuadMRT(RHICmdList, ...);
});
}
// 5. 각 View에 대해 Base Pass 렌더링
for (int32 ViewIndex = 0; ViewIndex < InViews.Num(); ++ViewIndex)
{
FViewInfo& View = InViews[ViewIndex];
if (bDoParallelBasePass)
{
// Parallel Dispatch
GraphBuilder.AddDispatchPass(
RDG_EVENT_NAME("BasePassParallel"),
PassParameters,
ERDGPassFlags::Raster | ERDGPassFlags::NeverCull,
[Pass, PassParameters](FRDGDispatchPassBuilder& DispatchPassBuilder)
{
Pass->Dispatch(DispatchPassBuilder, &PassParameters->InstanceCullingDrawParams);
});
}
else
{
// Single-threaded Draw
GraphBuilder.AddPass(...);
}
}
}
G-Buffer 레이아웃 상세 #
// Engine/Source/Runtime/Renderer/Internal/SceneTextures.h
// Engine/Source/Runtime/RenderCore/Public/GBufferInfo.h
// 기본 G-Buffer 슬롯 (EGBufferSlot enum)
GBS_SceneColor // RGB 11.11.10 - 최종 라이팅 결과 (Base Pass에서는 Emissive만)
GBS_WorldNormal // RGB 10.10.10 - Octahedron 인코딩된 월드 노멀
GBS_PerObjectGBufferData // 2 bits - 오브젝트별 데이터
GBS_Metallic // R8 - 금속성
GBS_Specular // R8 - 스페큘러 강도
GBS_Roughness // R8 - 거칠기
GBS_ShadingModelId // 4 bits - 셰이딩 모델 ID (Default, Subsurface, Cloth 등)
GBS_SelectiveOutputMask // 4 bits - 선택적 출력 마스크
GBS_BaseColor // RGB8 - 기본 색상 (Albedo)
GBS_GenericAO // R8 - Ambient Occlusion
GBS_Velocity // RG float16 - 모션 벡터
GBS_CustomData // RGBA8 - 셰이딩 모델별 커스텀 데이터
실제 렌더 타겟 패킹:
GBufferA (R10G10B10A2):
- RGB: World Normal (Octahedron 인코딩)
- A: Per-Object Data (2 bits)
GBufferB (R8G8B8A8):
- R: Metallic
- G: Specular
- B: Roughness
- A: ShadingModelID (4 bits) | SelectiveOutputMask (4 bits)
GBufferC (R8G8B8A8):
- RGB: Base Color
- A: Indirect Irradiance 또는 AO
GBufferD (R8G8B8A8): - 셰이딩 모델별 커스텀 데이터
- Default Lit: 미사용
- Subsurface: Subsurface Color
- Clear Coat: Clear Coat 강도, 거칠기
- Cloth: Fuzz Color
- Eye: Iris Normal, Iris Distance
GBufferE (R8G8B8A8): - 선택적 (bHasPrecShadowFactor)
- RGBA: Precomputed Shadow Factor, Sky Occlusion
GBufferF (R8G8B8A8): - 선택적 (bHasTangent)
- RGB: World Tangent
- A: Anisotropy
Velocity (R16G16_FLOAT): - 선택적 (bHasVelocity)
- RG: Screen Space Motion Vector
Shading Model별 G-Buffer 사용 #
| Shading Model | GBufferD 사용 | 추가 데이터 |
|---|---|---|
| Default Lit | 미사용 | - |
| Subsurface | RGB: Subsurface Color | Opacity in A |
| Preintegrated Skin | RGB: Subsurface Color | - |
| Clear Coat | R: Clear Coat, G: Roughness | Bottom Normal |
| Subsurface Profile | RGB: Subsurface Profile ID | - |
| Two Sided Foliage | RGB: Subsurface Color | - |
| Hair | RG: Tangent, B: Specular | Backlit in GBufferE |
| Cloth | RGB: Fuzz Color | - |
| Eye | RG: Iris Normal, B: Iris Mask | Iris Distance |
Nanite Base Pass 통합 #
Nanite 메시는 전통적인 버텍스 파이프라인 대신 Visibility Buffer 방식을 사용합니다:
// Engine/Source/Runtime/Renderer/Private/Nanite/NaniteRender.cpp
void Nanite::DrawBasePass(
FRDGBuilder& GraphBuilder,
const FSceneRenderer& SceneRenderer,
const FScene& Scene,
const FViewInfo& View,
const FRasterResults& RasterResults,
FSceneTextures& SceneTextures,
FNaniteShadingCommands& ShadingCommands)
{
// 1. Visibility Buffer에서 삼각형 ID, 바리센트릭 좌표 읽기
// 2. Material Depth Pass: 머티리얼별 깊이 기록
// 3. Deferred Material Pass: G-Buffer에 머티리얼 속성 기록
// - Compute Shader로 Visibility Buffer를 디코딩
// - 픽셀별로 해당 머티리얼 셰이더 실행
}
Nanite Visibility Buffer 구조:
Visibility Buffer (R32_UINT):
- Bits 0-6: Triangle ID (128개 삼각형/클러스터)
- Bits 7-31: Cluster ID
Depth Buffer: 표준 24-bit Depth
Nanite vs Traditional Base Pass:
| 항목 | Traditional | Nanite |
|---|---|---|
| 버텍스 처리 | VS로 변환 | GPU-driven Rasterizer |
| 오버드로 | Depth Prepass로 감소 | Visibility Buffer로 완전 제거 |
| 머티리얼 셰이딩 | Forward 스타일 | Deferred Material Pass |
| LOD | CPU 선택 | GPU 클러스터 단위 연속 LOD |
| 컬링 | CPU + GPU | 완전 GPU-driven |
DBuffer Decal 통합 #
// Base Pass에서 DBuffer Decal 적용
if (DBufferTextures.IsValid())
{
// DBufferA: Base Color Decal
// DBufferB: Normal Decal
// DBufferC: Roughness/Metallic/AO Decal
// → G-Buffer 값에 블렌딩
}
Substrate (실험적 렌더링 모델) #
UE5.3+에서 도입된 새로운 머티리얼 시스템으로, 기존 G-Buffer 대신 더 유연한 BSDF 레이어 시스템을 사용합니다:
// Substrate 활성화 시 추가 MRT
if (Substrate::IsSubstrateEnabled())
{
Substrate::AppendSubstrateMRTs(Renderer, BasePassTextureCount, BasePassTextures);
// SubstrateTopLayerTexture, SubstrateClosureOffsetTexture 등 추가
}
Base Pass 성능 최적화 #
| 최적화 기법 | 설명 |
|---|---|
| Parallel Command Encoding | CVarParallelBasePass로 멀티스레드 Draw 생성 |
| State Sorting | PSO, Texture 바인딩 순으로 정렬하여 State Change 최소화 |
| Instancing | 동일 메시/머티리얼 인스턴스 배칭 |
| GPU Scene | Primitive 데이터를 GPU Buffer에 캐싱 |
| Early-Z Rejection | Depth Prepass 결과로 불필요한 PS 실행 제거 |
| Async Compute Overlap | Base Pass와 독립적인 Compute 작업 병렬화 |
Shadow Depth Rendering #
각 광원에 대한 Shadow Map을 생성합니다. UE5는 기존 Cascaded Shadow Maps(CSM)과 새로운 Virtual Shadow Maps(VSM) 두 가지 시스템을 지원합니다.
Shadow Map 유형 및 선택 #
| 유형 | 대상 광원 | 특징 |
|---|---|---|
| Cascaded Shadow Maps (CSM) | Directional Light | 카메라 거리 기반 분할, 전통적 방식 |
| Per-Object Shadows | Spot/Point Light | 오브젝트 단위 섀도우, 작은 광원 |
| Virtual Shadow Maps (VSM) | 모든 광원 | 가상화된 고해상도 섀도우, UE5 기본값 |
RenderShadowDepthMaps 전체 흐름 #
// Engine/Source/Runtime/Renderer/Private/ShadowDepthRendering.cpp:1678
void FSceneRenderer::RenderShadowDepthMaps(
FRDGBuilder& GraphBuilder,
FDynamicShadowsTaskData* DynamicShadowsTaskData,
FInstanceCullingManager& InstanceCullingManager,
FRDGExternalAccessQueue& ExternalAccessQueue)
{
// 조기 종료 조건
if (!ViewFamily.EngineShowFlags.DynamicShadows)
{
bShadowDepthRenderCompleted = true;
return;
}
RDG_EVENT_SCOPE_STAT(GraphBuilder, ShadowDepths, "ShadowDepths");
// 1. Dynamic Shadow Mesh Pass 완료 대기
// - 병렬로 생성된 Shadow Mesh Draw Command 수집
if (DynamicShadowsTaskData)
{
FinishDynamicShadowMeshPassSetup(GraphBuilder, DynamicShadowsTaskData);
}
// 2. Instance Culling 배치 시작
// - Shadow View에 대한 Culling 작업 등록
InstanceCullingManager.BeginDeferredCulling(GraphBuilder);
// 3. Virtual Shadow Maps 렌더링 (UE5 기본값)
FShadowSceneRenderer* ShadowSceneRenderer = GetSceneExtensionsRenderers().GetRendererPtr<FShadowSceneRenderer>();
if (ShadowSceneRenderer)
{
ShadowSceneRenderer->RenderVirtualShadowMaps(GraphBuilder, bNaniteEnabled);
}
// 4. 전통적 Shadow Map Atlas 렌더링 (Non-VSM)
// - Directional Light CSM
// - Spot/Point Light Per-Object Shadows
RenderShadowDepthMapAtlases(GraphBuilder);
// 5. Cubemap Shadow Maps (Point Light 전용)
for (FSortedShadowMapAtlas& ShadowMap : SortedShadowsForShadowDepthPass.ShadowMapCubemaps)
{
FProjectedShadowInfo* ProjectedShadowInfo = ShadowMap.Shadows[0];
// Cubemap 6면 렌더링
ProjectedShadowInfo->RenderDepth(GraphBuilder, this, ShadowDepthTexture,
bDoParallelDispatch, bDoCrossGPUCopy);
// Nanite Shadow 통합
if (bNaniteEnabled && CVarNaniteShadows.GetValueOnRenderThread())
{
for (int32 FaceIndex = 0; FaceIndex < 6; FaceIndex++)
{
Nanite::RenderShadowDepths(GraphBuilder, ...);
}
}
}
bShadowDepthRenderCompleted = true;
}
Cascaded Shadow Maps (CSM) 상세 #
// Engine/Source/Runtime/Renderer/Private/ShadowSetup.cpp
void FProjectedShadowInfo::SetupWholeSceneProjection(
FLightSceneInfo* InLightSceneInfo,
FViewInfo* InDependentView,
const FWholeSceneProjectedShadowInitializer& Initializer,
uint32 InResolutionX,
uint32 InResolutionY,
uint32 InBorderSize,
bool bInReflectiveShadowMap)
{
// Cascade 분할 계산
// - Practical Split Scheme: Log + Linear 혼합
// - 각 Cascade의 Near/Far 평면 결정
// Cascade별 Shadow Matrix 계산
// - Light Space View Matrix
// - Light Space Projection Matrix (Orthographic)
}
CSM Cascade 분할:
// Practical Split Scheme
float SplitNear = Mix(
NearClip * pow(FarClip / NearClip, CascadeIndex / NumCascades), // Logarithmic
NearClip + (FarClip - NearClip) * (CascadeIndex / NumCascades), // Linear
Lambda // 혼합 비율 (0.5 ~ 0.9)
);
Virtual Shadow Maps (VSM) 상세 #
VSM은 UE5의 핵심 섀도우 시스템으로, 16K×16K 가상 텍스처를 페이지 단위로 관리합니다.
// Engine/Source/Runtime/Renderer/Private/VirtualShadowMaps/VirtualShadowMapArray.cpp
void FVirtualShadowMapArray::RenderVirtualShadowMapsHw(FRDGBuilder& GraphBuilder, ...)
{
// 1. Page Table 업데이트
// - 화면에 보이는 영역만 페이지 할당
// - LOD 기반 해상도 선택
// 2. Physical Page Pool 관리
// - LRU 기반 페이지 교체
// - 캐싱을 통한 재사용
// 3. Nanite 통합 렌더링
// - Nanite 클러스터를 직접 VSM에 래스터화
// - GPU-driven 컬링 + 렌더링
// 4. Non-Nanite 메시 렌더링
// - 전통적 방식으로 VSM 페이지에 렌더링
}
VSM 아키텍처: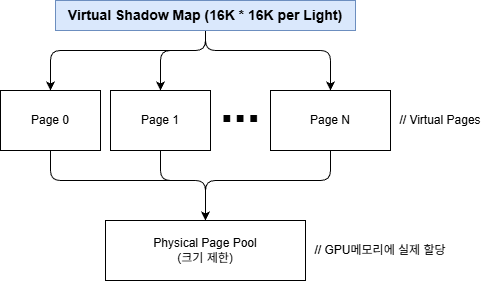
VSM vs CSM 비교:
| 항목 | CSM | VSM |
|---|---|---|
| 해상도 | 고정 (2K~4K per cascade) | 가변 (최대 16K 가상) |
| 메모리 | 예측 가능, 고정 | 동적 할당, 효율적 |
| 품질 | Cascade 경계에서 품질 저하 | 균일한 품질 |
| Nanite 통합 | 별도 렌더링 | 네이티브 통합 |
| 캐싱 | 없음 | 페이지 단위 캐싱 |
| 적합한 씬 | 중소규모 | 대규모 오픈월드 |
Shadow Map Atlas #
// Engine/Source/Runtime/Renderer/Private/ShadowDepthRendering.cpp
void FSceneRenderer::RenderShadowDepthMapAtlases(FRDGBuilder& GraphBuilder)
{
// Shadow Map들을 Atlas 텍스처에 패킹
// - 작은 Shadow Map들을 하나의 큰 텍스처에 배치
// - Draw Call 최소화
for (FSortedShadowMapAtlas& Atlas : SortedShadowsForShadowDepthPass.ShadowMapAtlases)
{
FRDGTextureRef ShadowDepthTexture = GraphBuilder.RegisterExternalTexture(
Atlas.RenderTargets.DepthTarget);
for (FProjectedShadowInfo* Shadow : Atlas.Shadows)
{
// 각 Shadow를 Atlas 내 할당된 영역에 렌더링
Shadow->RenderDepth(GraphBuilder, this, ShadowDepthTexture, ...);
}
}
}
Shadow Depth Rendering 최적화 #
| 최적화 | 설명 |
|---|---|
| Shadow Caching | 정적 오브젝트 섀도우 캐싱 (VSM) |
| Distance Fade | 원거리 섀도우 페이드 아웃 |
| Cascade Selection | 동적 Cascade 수 조절 |
| Page Invalidation | 변경된 페이지만 재렌더링 (VSM) |
| Nanite Integration | Nanite LOD와 Shadow LOD 연동 |
| Async Shadow Setup | 병렬 Shadow Mesh Pass 생성 |
Shadow Projection (Lighting Pass에서 사용) #
// Shadow Map 샘플링 및 PCF 필터링
float SampleShadowMap(float3 ShadowCoord, float2 ShadowMapSize)
{
// 1. Depth 비교
float ReceiverDepth = ShadowCoord.z;
float ShadowMapDepth = ShadowDepthTexture.Sample(ShadowCoord.xy);
// 2. PCF (Percentage Closer Filtering)
float Shadow = 0;
for (int i = 0; i < NumSamples; i++)
{
float2 Offset = PoissonDisk[i] / ShadowMapSize;
Shadow += ShadowDepthTexture.Sample(ShadowCoord.xy + Offset) > ReceiverDepth ? 1 : 0;
}
return Shadow / NumSamples;
// 3. PCSS (Percentage Closer Soft Shadows) - 선택적
// - Blocker 검색 → Penumbra 크기 계산 → 가변 필터 크기
}
Lighting Pass #
G-Buffer 정보를 기반으로 최종 라이팅을 계산합니다. Deferred Shading의 핵심으로, 모든 광원의 기여도를 누적하여 SceneColor에 기록합니다.
광원 분류 체계 #
// Engine/Source/Runtime/Renderer/Private/LightSceneInfo.h
// FSortedLightSetSceneInfo 구조
SortedLights[0 ~ SimpleLightsEnd] // Simple Lights: 작은 범위, 섀도우 없음
SortedLights[SimpleLightsEnd ~ ClusteredSupportedEnd] // Clustered 지원 광원
SortedLights[ClusteredSupportedEnd ~ UnbatchedLightStart] // Batched Lights
SortedLights[UnbatchedLightStart ~ MegaLightsLightStart] // Unbatched: 개별 처리 (섀도우, IES 등)
SortedLights[MegaLightsLightStart ~ Num] // MegaLights 대상
RenderLights 전체 흐름 #
// Engine/Source/Runtime/Renderer/Private/LightRendering.cpp:1520
void FDeferredShadingSceneRenderer::RenderLights(
FRDGBuilder& GraphBuilder,
FMinimalSceneTextures& SceneTextures,
FRDGTextureRef LightingChannelsTexture,
const FSortedLightSetSceneInfo& SortedLightSet)
{
RDG_EVENT_SCOPE_STAT(GraphBuilder, Lights, "Lights");
// 1. Substrate Stencil 마킹 (Substrate 활성화 시)
// - Simple/Complex 머티리얼 영역을 Stencil로 구분
if (ViewFamily.EngineShowFlags.DirectLighting && Substrate::IsSubstrateEnabled())
{
Substrate::AddSubstrateStencilPass(GraphBuilder, Views, SceneTextures);
}
// 2. VSM Projection Mask 렌더링
// - Virtual Shadow Map의 섀도우 마스크 생성
FShadowSceneRenderer& ShadowSceneRenderer = GetSceneExtensionsRenderers().GetRenderer<FShadowSceneRenderer>();
ShadowSceneRenderer.RenderVirtualShadowMapProjectionMaskBits(GraphBuilder, SceneTextures);
// 3. Clustered Deferred Shading
// - 3D Light Grid를 통해 다수의 광원을 효율적으로 처리
if (ShouldUseClusteredDeferredShading(ViewFamily.GetShaderPlatform()) && AreLightsInLightGrid())
{
AddClusteredDeferredShadingPass(GraphBuilder, SceneTextures, SortedLightSet,
ShadowSceneRenderer.VirtualShadowMapMaskBits,
ShadowSceneRenderer.VirtualShadowMapMaskBitsHairStrands,
LightingChannelsTexture);
}
else if (SortedLightSet.SimpleLights.InstanceData.Num() > 0)
{
// Clustered 미사용 시 Standard Deferred
RenderSimpleLightsStandardDeferred(GraphBuilder, SceneTextures, SortedLightSet);
}
// 4. Unbatched Lights (개별 광원)
// - 섀도우 캐스팅, Light Function, IES Profile 등 복잡한 광원
for (int32 LightIndex = UnbatchedLightStart; LightIndex < SortedLights.Num(); LightIndex++)
{
const FSortedLightSceneInfo& SortedLight = SortedLights[LightIndex];
const FLightSceneInfo& LightSceneInfo = *SortedLight.LightSceneInfo;
// Stencil 볼륨 최적화
if (LightSceneInfo.Proxy->GetLightType() == LightType_Point ||
LightSceneInfo.Proxy->GetLightType() == LightType_Spot)
{
// Light Volume (Sphere/Cone)으로 영향 범위 제한
RenderLightForStencilVolume(GraphBuilder, LightSceneInfo, ...);
}
// 실제 라이팅 계산
RenderLight(GraphBuilder, SceneTextures, SortedLight, ...);
}
}
Clustered Deferred Shading 상세 #
View Frustum을 3D 그리드(클러스터)로 분할하고, 각 클러스터에 영향을 미치는 광원 목록을 사전 계산합니다.
// Engine/Source/Runtime/Renderer/Private/ClusteredDeferredShadingPass.cpp
void FDeferredShadingSceneRenderer::AddClusteredDeferredShadingPass(...)
{
// Substrate 머티리얼 타입별 분기
if (Substrate::IsSubstrateEnabled())
{
// 각 타일 타입별로 별도 패스
if (Substrate::GetSubstrateUsesTileType(View, ESubstrateTileType::EComplexSpecial))
InternalAddClusteredDeferredShadingPass(..., EClusteredShadingPass::Substrate);
if (Substrate::GetSubstrateUsesTileType(View, ESubstrateTileType::EComplex))
InternalAddClusteredDeferredShadingPass(...);
// ... ESingle, ESimple
}
else
{
// 기존 GBuffer 경로
InternalAddClusteredDeferredShadingPass(..., EClusteredShadingPass::GBuffer);
}
// Hair Strands 전용 패스
if (HairStrands::HasViewHairStrandsData(View))
{
FHairStrandsTransmittanceMaskData TransmittanceMask = RenderHairStrandsOnePassTransmittanceMask(...);
InternalAddClusteredDeferredShadingPass(..., EClusteredShadingPass::HairStrands);
}
}
Light Grid 구조:
View Frustum을 X × Y × Z 클러스터로 분할
┌─────────────────────────────────────┐
│ Near Plane │
│ ┌─────┬─────┬─────┬─────┐ │
│ │ C00 │ C01 │ C02 │ C03 │ Slice 0 │
│ ├─────┼─────┼─────┼─────┤ │
│ │ C10 │ C11 │ C12 │ C13 │ Slice 1 │
│ └─────┴─────┴─────┴─────┘ │
│ ... │
│ Far Plane │
└─────────────────────────────────────┘
각 클러스터(Cij): 해당 영역에 영향을 미치는 Light 인덱스 리스트 저장
Clustered Lighting 셰이더:
// ClusteredDeferredShadingPixelShader.usf
float3 CalculateClusteredLighting(float3 WorldPosition, ...)
{
// 1. 현재 픽셀의 클러스터 인덱스 계산
uint3 ClusterIndex = ComputeClusterIndex(ScreenUV, Depth);
// 2. 해당 클러스터의 Light 리스트 가져오기
uint LightListOffset = LightGrid[ClusterIndex].Offset;
uint LightCount = LightGrid[ClusterIndex].Count;
// 3. 각 광원에 대해 라이팅 계산
float3 Lighting = 0;
for (uint i = 0; i < LightCount; i++)
{
uint LightIndex = LightIndices[LightListOffset + i];
FLightData Light = GetLightData(LightIndex);
Lighting += CalculateLightContribution(Light, WorldPosition, Normal, ...);
}
return Lighting;
}
Standard Deferred Light Rendering #
개별 광원을 Full-screen Quad 또는 Light Volume으로 렌더링:
// Engine/Source/Runtime/Renderer/Private/LightRendering.cpp
void RenderLight(
FRDGBuilder& GraphBuilder,
const FMinimalSceneTextures& SceneTextures,
const FSortedLightSceneInfo& SortedLight,
...)
{
const FLightSceneInfo& LightSceneInfo = *SortedLight.LightSceneInfo;
// 1. Shadow Projection (섀도우 캐스팅 광원)
if (SortedLight.SortedShadowInfo.Num() > 0)
{
RenderProjectedShadows(GraphBuilder, LightSceneInfo, SortedLight.SortedShadowInfo);
}
// 2. Light Function 적용 (광원 마스킹)
if (LightSceneInfo.Proxy->GetLightFunctionMaterial())
{
RenderLightFunction(GraphBuilder, LightSceneInfo);
}
// 3. 실제 라이팅 계산
GraphBuilder.AddPass(
RDG_EVENT_NAME("StandardDeferredLighting"),
PassParameters,
ERDGPassFlags::Raster,
[&](FRHICommandList& RHICmdList)
{
// Light Volume 또는 Full-screen Quad
if (bUseLightVolume)
DrawLightVolume(RHICmdList, LightSceneInfo);
else
DrawFullScreenQuad(RHICmdList);
});
}
Stencil 볼륨 최적화 #
Point/Spot Light의 영향 범위를 Stencil로 마킹하여 불필요한 픽셀 셰이더 실행 방지:
1단계: Light Volume을 Depth Test + Stencil Write로 렌더링
→ 광원 영향 범위 내 픽셀만 Stencil 마킹
2단계: Full-screen Quad + Stencil Test로 라이팅 계산
→ Stencil 통과한 픽셀만 PS 실행
MegaLights (UE5.5+) #
수천 개의 광원을 효율적으로 처리하는 새로운 시스템:
// Engine/Source/Runtime/Renderer/Private/MegaLights/MegaLights.cpp
void FDeferredShadingSceneRenderer::RenderMegaLights(FRDGBuilder& GraphBuilder, ...)
{
// 1. Importance Sampling 기반 광원 선택
// - 각 픽셀에 가장 중요한 N개 광원 선택
// - 광원 강도, 거리, 방향 기반 확률 분포
// 2. Stochastic Lighting
// - 선택된 광원만 샘플링
// - 확률에 따른 가중치 적용
// 3. Temporal Accumulation
// - 여러 프레임에 걸쳐 결과 누적
// - 노이즈 감소 + 수렴
// 4. Denoising
// - Spatial/Temporal 필터링
// - 최종 결과 안정화
}
Lighting Pass 성능 최적화 #
| 최적화 | 설명 | 효과 |
|---|---|---|
| Clustered Shading | 3D Grid로 광원 관리 | O(N×M) → O(N×k) |
| Stencil Volumes | 광원 범위 제한 | PS 실행 감소 |
| Tiled Deferred | 2D 타일 기반 처리 | 메모리 대역폭 감소 |
| Light Sorting | 복잡도별 분류 | 배칭 효율 증가 |
| VSM Integration | 가상 섀도우 맵 | 고품질 + 효율성 |
| MegaLights | 확률적 샘플링 | 수천 개 광원 처리 |
Post Processing #
최종 이미지 품질 향상을 위한 후처리 파이프라인입니다. UE5의 포스트 프로세싱은 RDG 기반으로 구현되어 있으며, TOverridePassSequence를 통해 패스 순서와 활성화 여부를 관리합니다.
Post Processing 파이프라인 아키텍처 #
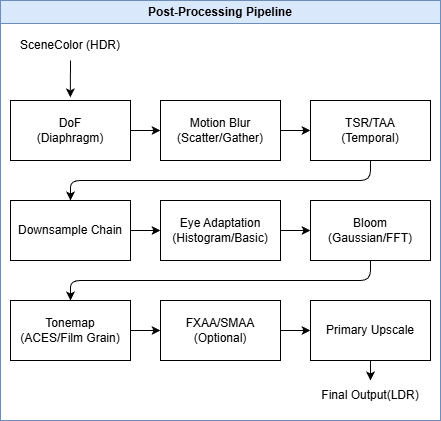
AddPostProcessingPasses 메인 엔트리 포인트 #
// Engine/Source/Runtime/Renderer/Private/PostProcess/PostProcessing.cpp:347
void AddPostProcessingPasses(
FRDGBuilder& GraphBuilder,
const FViewInfo& View,
int32 ViewIndex,
FSceneUniformBuffer& SceneUniformBuffer,
EDiffuseIndirectMethod DiffuseIndirectMethod,
EReflectionsMethod ReflectionsMethod,
const FPostProcessingInputs& Inputs,
const Nanite::FRasterResults* NaniteRasterResults,
FInstanceCullingManager& InstanceCullingManager,
FVirtualShadowMapArray* VirtualShadowMapArray,
FLumenSceneFrameTemporaries& LumenFrameTemporaries,
const FSceneWithoutWaterTextures& SceneWithoutWaterTextures,
FScreenPassTexture TSRFlickeringInput,
FRDGTextureRef& InstancedEditorDepthTexture)
{
// Pass Sequence 정의 (PostProcessing.cpp:441)
enum class EPass : uint32
{
MotionBlur,
PostProcessMaterialBeforeBloom,
Tonemap,
FXAA,
SMAA,
PostProcessMaterialAfterTonemapping,
// ... Visualize passes ...
PrimaryUpscale,
SecondaryUpscale,
AlphaInvert,
MAX
};
TOverridePassSequence<EPass> PassSequence(ViewFamilyOutput);
// TAA 설정 결정
const EMainTAAPassConfig TAAConfig = GetMainTAAPassConfig(View);
// Temporal Upscaler 분기 (PostProcessing.cpp:975)
if (TAAConfig == EMainTAAPassConfig::TSR)
{
Outputs = AddMainTemporalSuperResolutionPasses(GraphBuilder, View, UpscalerPassInputs);
}
else if (TAAConfig == EMainTAAPassConfig::TAA)
{
Outputs = AddGen4MainTemporalAAPasses(GraphBuilder, View, UpscalerPassInputs);
}
else if (TAAConfig == EMainTAAPassConfig::ThirdParty)
{
Outputs = AddThirdPartyTemporalUpscalerPasses(GraphBuilder, View, UpscalerPassInputs);
}
}
Motion Blur #
카메라 및 오브젝트 움직임에 의한 블러 효과를 시뮬레이션합니다.
// Engine/Source/Runtime/Renderer/Private/PostProcess/PostProcessMotionBlur.cpp:128
bool IsMotionBlurEnabled(const FViewInfo& View)
{
if (View.GetFeatureLevel() < ERHIFeatureLevel::SM5)
{
return false;
}
const int32 MotionBlurQuality = GetMotionBlurQualityFromCVar();
const FSceneViewFamily& ViewFamily = *View.Family;
return ViewFamily.EngineShowFlags.PostProcessing
&& ViewFamily.EngineShowFlags.MotionBlur
&& View.FinalPostProcessSettings.MotionBlurAmount > 0.001f
&& View.FinalPostProcessSettings.MotionBlurMax > 0.001f
&& ViewFamily.bRealtimeUpdate
&& MotionBlurQuality > 0
&& (CVarAllowMotionBlurInVR->GetInt() != 0 || !GEngine->StereoRenderingDevice.IsValid());
}
Motion Blur 처리 흐름: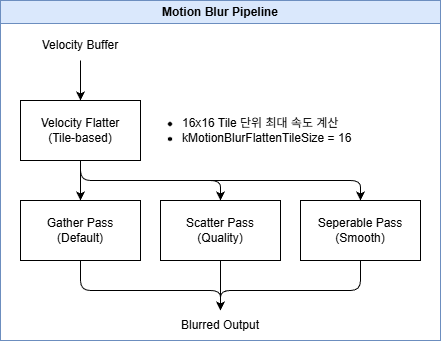
Scatter vs Gather 결정 로직:
// Engine/Source/Runtime/Renderer/Private/PostProcess/PostProcessMotionBlur.cpp:153
bool IsMotionBlurScatterRequired(const FViewInfo& View, const FScreenPassTextureViewport& SceneViewport)
{
const float ViewportWidth = SceneViewport.Rect.Width();
const float VelocityMax = View.FinalPostProcessSettings.MotionBlurMax / 100.0f;
// 타일 단위로 변환 (0.5 / 16.0 = 양방향 블러 + 타일 크기)
const float VelocityMaxInTiles = VelocityMax * ViewportWidth * (0.5f / 16.0f);
// Gather 방식으로 처리 가능한 최대 타일 거리
const float TileDistanceMaxGathered = 3.0f;
// 최대 속도가 Gather 한계를 초과하면 Scatter 사용
const bool bIsScatterRequiredByVelocityLength = VelocityMaxInTiles > TileDistanceMaxGathered;
// 시네마틱 일시정지 시 고품질 Scatter 사용
const bool bInPausedCinematic = (ViewState && ViewState->SequencerState == ESS_Paused);
return bIsScatterRequiredByUser || bIsScatterRequiredByVelocityLength;
}
TSR (Temporal Super Resolution) #
UE5의 핵심 업스케일링 기술로, 낮은 렌더링 해상도에서 고품질 출력을 생성합니다.
// Engine/Source/Runtime/Renderer/Private/PostProcess/TemporalSuperResolution.cpp
// TSR 주요 설정 파라미터
// 히스토리 샘플 수 (기본 16, 최대 32)
TAutoConsoleVariable<float> CVarTSRHistorySampleCount(
TEXT("r.TSR.History.SampleCount"), 16.0f,
TEXT("Maximum number sample for each output pixel in the history."));
// 히스토리 해상도 배율 (기본 100%, 최대 200%)
TAutoConsoleVariable<float> CVarTSRHistorySP(
TEXT("r.TSR.History.ScreenPercentage"), 100.0f,
TEXT("Resolution multiplier of the history of TSR."));
// Async Compute 설정
TAutoConsoleVariable<int32> CVarTSRAsyncCompute(
TEXT("r.TSR.AsyncCompute"), 2,
TEXT("0: Disabled\n")
TEXT("1: Independent passes only\n")
TEXT("2: Depth/Velocity dependent passes (default)\n")
TEXT("3: All passes on async compute"));
TSR 파이프라인 구조: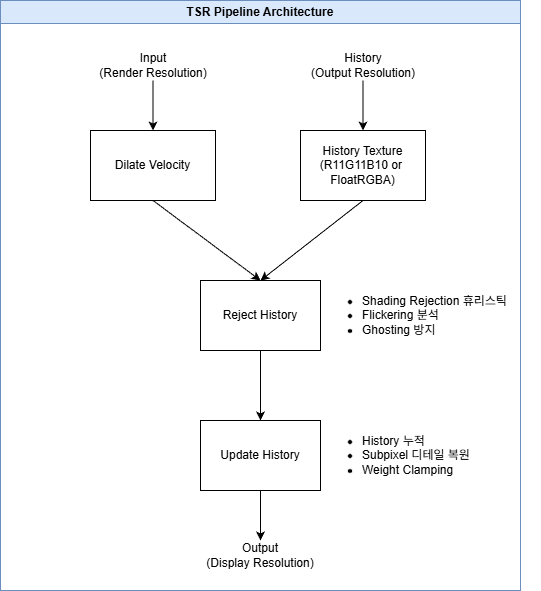
TSR Shading Rejection 휴리스틱:
// TSR의 핵심 품질 파라미터
// Engine/Source/Runtime/Renderer/Private/PostProcess/TemporalSuperResolution.cpp:122
// Rejection 후 히스토리 샘플 수 (낮을수록 선명, 높을수록 안정)
TAutoConsoleVariable<float> CVarTSRHistoryRejectionSampleCount(
TEXT("r.TSR.ShadingRejection.SampleCount"), 2.0f,
TEXT("Lower values = higher clarity after rejection, but more instability"));
// Flickering 감지 활성화 (모아레 패턴, 복잡한 지오메트리 처리)
TAutoConsoleVariable<int32> CVarTSRFlickeringEnable(
TEXT("r.TSR.ShadingRejection.Flickering"), 1,
TEXT("Temporal analysis to stabilize flickering pixels"));
// Flickering 감지 주기 (프레임 단위)
TAutoConsoleVariable<float> CVarTSRFlickeringPeriod(
TEXT("r.TSR.ShadingRejection.Flickering.Period"), 2.0f,
TEXT("Frame frequency threshold for flickering detection"));
Eye Adaptation (자동 노출) #
씬의 밝기에 따라 카메라 노출을 자동으로 조정합니다.
// Engine/Source/Runtime/Renderer/Private/PostProcess/PostProcessEyeAdaptation.cpp:265
EAutoExposureMethod GetAutoExposureMethod(const FViewInfo& View)
{
EAutoExposureMethod AutoExposureMethod = View.FinalPostProcessSettings.AutoExposureMethod;
// Feature Level에 따른 fallback
if (!IsAutoExposureMethodSupported(View.GetFeatureLevel(), AutoExposureMethod))
{
AutoExposureMethod = IsAutoExposureMethodSupported(View.GetFeatureLevel(),
EAutoExposureMethod::AEM_Basic) ? EAutoExposureMethod::AEM_Basic
: EAutoExposureMethod::AEM_Manual;
}
return ApplyEyeAdaptationQuality(AutoExposureMethod);
}
Eye Adaptation 방식 비교:
| 방식 | 설명 | 사용 사례 |
|---|---|---|
| AEM_Histogram | 히스토그램 기반 노출 계산 | 고품질, 정확한 노출 |
| AEM_Basic | 평균 휘도 기반 간단한 계산 | 성능 우선 |
| AEM_Manual | 고정 노출 값 | 예술적 제어 필요 시 |
// Histogram Eye Adaptation (PostProcessing.cpp:1275)
EyeAdaptationBuffer = AddHistogramEyeAdaptationPass(
GraphBuilder, View,
EyeAdaptationParameters,
LocalExposureParameters,
HistogramTexture,
bLocalExposureEnabled && View.FinalPostProcessSettings.LocalExposureMethod == ELocalExposureMethod::Bilateral);
// Basic Eye Adaptation (PostProcessing.cpp:1264)
EyeAdaptationBuffer = AddBasicEyeAdaptationPass(
GraphBuilder, View,
EyeAdaptationParameters,
LocalExposureParameters,
SceneDownsampleChain.GetLastTexture(),
LastEyeAdaptationBuffer,
bLocalExposureEnabled);
Bloom #
밝은 영역에서 발산되는 빛 번짐 효과를 구현합니다.
// Engine/Source/Runtime/Renderer/Private/PostProcess/PostProcessBloomSetup.cpp:197
FScreenPassTexture AddGaussianBloomPasses(
FRDGBuilder& GraphBuilder,
const FViewInfo& View,
const FTextureDownsampleChain* SceneDownsampleChain)
{
const EBloomQuality BloomQuality = GetBloomQuality();
// 품질별 다운샘플 스테이지 수
const uint32 BloomQualityToSceneDownsampleStage[] =
{
static_cast<uint32>(-1), // Disabled
3, // Q1
3, // Q2
4, // Q3
5, // Q4
6 // Q5
};
// 각 스테이지별 블룸 설정
FBloomStage BloomStages[] =
{
{ Settings.Bloom6Size, Settings.Bloom6Tint }, // 가장 넓은 블러
{ Settings.Bloom5Size, Settings.Bloom5Tint },
{ Settings.Bloom4Size, Settings.Bloom4Tint },
{ Settings.Bloom3Size, Settings.Bloom3Tint },
{ Settings.Bloom2Size, Settings.Bloom2Tint },
{ Settings.Bloom1Size, Settings.Bloom1Tint } // 가장 좁은 블러
};
// 각 스테이지에 Gaussian Blur 적용
for (uint32 StageIndex = 0; StageIndex < BloomStageCount; ++StageIndex)
{
FGaussianBlurInputs PassInputs;
PassInputs.Filter = SceneDownsampleChain->GetTexture(SourceIndex);
PassInputs.Additive = PassOutputs; // 이전 결과와 합성
PassInputs.KernelSizePercent = BloomStage.Size * Settings.BloomSizeScale;
PassInputs.TintColor = BloomStage.Tint * TintScale;
PassOutputs = AddGaussianBlurPass(GraphBuilder, View, PassInputs);
}
}
Bloom 타입 비교:
Tonemapping #
HDR 씬 컬러를 디스플레이 가능한 LDR로 변환합니다.
// Engine/Source/Runtime/Renderer/Private/PostProcess/PostProcessTonemap.cpp:227
FTonemapperOutputDeviceParameters GetTonemapperOutputDeviceParameters(const FSceneViewFamily& Family)
{
EDisplayOutputFormat OutputDeviceValue;
if (Family.SceneCaptureSource == SCS_FinalColorHDR)
{
OutputDeviceValue = EDisplayOutputFormat::HDR_LinearNoToneCurve;
}
else if (Family.SceneCaptureSource == SCS_FinalToneCurveHDR)
{
OutputDeviceValue = EDisplayOutputFormat::HDR_LinearWithToneCurve;
}
else
{
OutputDeviceValue = Family.RenderTarget->GetDisplayOutputFormat();
}
FTonemapperOutputDeviceParameters Parameters;
Parameters.InverseGamma = InvDisplayGammaValue;
Parameters.OutputDevice = static_cast<uint32>(OutputDeviceValue);
Parameters.OutputGamut = static_cast<uint32>(Family.RenderTarget->GetDisplayColorGamut());
Parameters.OutputMaxLuminance = HDRGetDisplayMaximumLuminance();
return Parameters;
}
Tonemapper 셰이더 파라미터:
// Engine/Source/Runtime/Renderer/Private/PostProcess/PostProcessTonemap.cpp:287
BEGIN_SHADER_PARAMETER_STRUCT(FTonemapParameters, )
SHADER_PARAMETER_STRUCT_INCLUDE(FViewShaderParameters, View)
SHADER_PARAMETER_STRUCT_INCLUDE(FFilmGrainParameters, FilmGrain)
SHADER_PARAMETER_STRUCT_INCLUDE(FTonemapperOutputDeviceParameters, OutputDevice)
// Color Grading LUT
SHADER_PARAMETER_RDG_TEXTURE(Texture2D, ColorGradingLUT)
SHADER_PARAMETER(float, LUTSize)
SHADER_PARAMETER(float, InvLUTSize)
// Bloom 합성
SHADER_PARAMETER_RDG_TEXTURE(Texture2D, BloomTexture)
SHADER_PARAMETER(FScreenTransform, ColorToBloom)
// Eye Adaptation
SHADER_PARAMETER_RDG_BUFFER_SRV(StructuredBuffer<float4>, EyeAdaptationBuffer)
// Film 파라미터 (ACES Tonemapper)
SHADER_PARAMETER(float, FilmSlope)
SHADER_PARAMETER(float, FilmToe)
SHADER_PARAMETER(float, FilmShoulder)
SHADER_PARAMETER(float, FilmBlackClip)
SHADER_PARAMETER(float, FilmWhiteClip)
// Chromatic Aberration
SHADER_PARAMETER(FVector4f, ChromaticAberrationParams)
// Quantization Dithering (밴딩 방지)
SHADER_PARAMETER(float, BackbufferQuantizationDithering)
END_SHADER_PARAMETER_STRUCT()
Tonemapper Permutation:
// Shader Permutation 정의
namespace TonemapperPermutation
{
class FTonemapperGammaOnlyDim : SHADER_PERMUTATION_BOOL("USE_GAMMA_ONLY");
class FTonemapperLocalExposureDim : SHADER_PERMUTATION_INT("LOCAL_EXPOSURE_MODE", 3);
class FTonemapperSharpenDim : SHADER_PERMUTATION_BOOL("USE_SHARPEN");
class FTonemapperFilmGrainDim : SHADER_PERMUTATION_BOOL("USE_FILM_GRAIN");
class FTonemapperColorFringeDim : SHADER_PERMUTATION_BOOL("USE_COLOR_FRINGE");
class FTonemapperAlphaChannelDim : SHADER_PERMUTATION_BOOL("DIM_ALPHA_CHANNEL");
}
Downsample Chain #
Eye Adaptation과 Bloom을 위한 다운샘플 체인을 생성합니다.
// PostProcessing.cpp:1238-1251
if (bProduceSceneColorChain)
{
const bool bLogLumaInAlpha = bBasicEyeAdaptationEnabled;
SceneDownsampleChain.Init(
GraphBuilder, View,
EyeAdaptationParameters,
bProcessEighthResolution ? EighthResSceneColor
: (bProcessQuarterResolution ? QuarterResSceneColor : HalfResSceneColor),
DownsampleChainQuality,
6, // 6단계 다운샘플
bLogLumaInAlpha,
TEXT("Scene"),
bProcessEighthResolution ? 3 : (bProcessQuarterResolution ? 2 : 1));
}
다운샘플 체인 구조: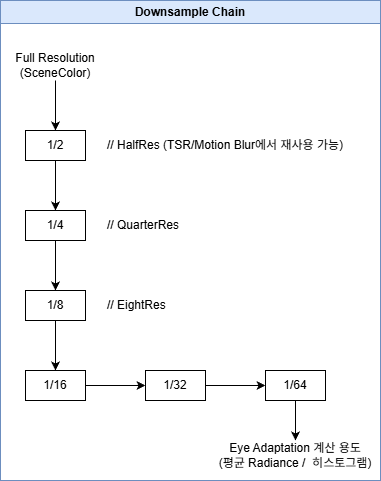
Post Processing 성능 최적화 #
| 최적화 기법 | 설명 | 효과 |
|---|---|---|
| TSR Async Compute | 독립 패스를 비동기로 실행 | GPU 활용률 향상 |
| R11G11B10 History | 히스토리 메모리 포맷 최적화 | 대역폭 50% 감소 |
| Downsample Reuse | TSR/Motion Blur 다운샘플 재사용 | 중복 연산 제거 |
| Pass Merging | Film Grain + Sharpen + Tonemap 통합 | 드로우콜 감소 |
| Compute Shaders | PS 대신 CS 사용 | 캐시 효율성 향상 |
| Quarter/Eighth Res | Eye Adaptation용 저해상도 처리 | 대역폭 75% 감소 |
Post Processing CVar 제어 #
// 주요 품질/성능 제어 CVar
r.MotionBlurQuality // 0-4: Motion Blur 품질
r.BloomQuality // 0-5: Bloom 품질 (다운샘플 단계 수)
r.Tonemapper.Sharpen // -1~10: 샤프닝 강도
r.TSR.History.ScreenPercentage // 100-200: TSR 히스토리 해상도
r.TSR.History.SampleCount // 8-32: 히스토리 누적 샘플 수
r.EyeAdaptationQuality // 0-2: Eye Adaptation 품질
r.PostProcessing.PropagateAlpha // 알파 채널 전파 (VFX 합성용)
리소스 의존성 요약 #
각 패스 간의 리소스 읽기/쓰기 의존성:
| 패스 | 읽기 | 쓰기 |
|---|---|---|
| Visibility | Primitive Bounds, HZB (이전 프레임) | VisibilityMap |
| Depth Prepass | VisibilityMap | SceneDepth |
| HZB Build | SceneDepth | HZB Texture |
| Base Pass | HZB, VisibilityMap | GBuffer A-F, Velocity |
| Shadow Depth | Shadow Casters, VisibilityMap | Shadow Maps, VSM Page Table |
| Lighting | GBuffer A-F, Shadow Maps, VSM | SceneColor |
| Post Processing | SceneColor, Depth, Velocity, History | Final Output, History |